
How is it with ChatGPT and the data you feed into it? Does it learn from the conversations you as a user have with it? This blog post aims to demystify key questions around ChatGPT, focusing specifically on how it learns and its data usage. Let’s get started!
The short answer: Well, yes, maybe and no. Mostly no.
Let’s split that question into two subjects to see how it works. First, we can look at whether ChatGPT continuously learns from the conversation it has with the users. That’s where the “mostly no” answer comes from. Secondly, we can have a look at how OpenAI, the company behind ChatGPT, can potentially use the conversations to improve their language models in the future. This is where the “yes, maybe” comes into play.
The short answer: No.
The long answer requires us to look a bit at how ChatGPT and the underlying language models work. ChatGPT uses either GPT-3.5 or GPT-4 to generate the answers to the users questions or conversation. “GPT” is short for Generative Pre-trained Transformer. “Pre-trained” is the keyword here.
The term "pre-trained" signifies the phase in which the model is initially trained on a massive corpus of internet text including a lot of openly accessible texts as well as licensed text pieces in the case of GPT-4. This pre-training process enables GPT-3.5 or GPT-4 to understand the nuances of language and context by predicting the next word in a sentence based on the patterns it recognizes from the vast amount of data it was trained on.
A common misconception about AI models like ChatGPT is that they learn and improve over time from the input and output of their interactions with users. However, this is not the case. Once the pre-training phase is completed, these models don't learn or adapt from user interactions or inputs. Instead, they generate responses based on the patterns and knowledge they've learned during this initial training phase. The models have no memory of past interactions, do not store personal data, and do not improve over time based on the conversations they have. This is a crucial point to understand when considering the functionality of ChatGPT and other AI language models (you can read more about that here or here).
So ChatGPT only has its knowledge from its pre-training as well as the context you are giving it as a user in a given conversation. You do not need to worry about that. However, something you might have to worry about is how OpenAI trains its future language models. Let’s look at that…
The short answer: Yes, and even if they won’t, you should probably take care!
When you log in to ChatGPT you are met with a screen saying: “Conversations may be reviewed by our Al trainers to improve our systems. Please don't share any sensitive information in your conversations.”.
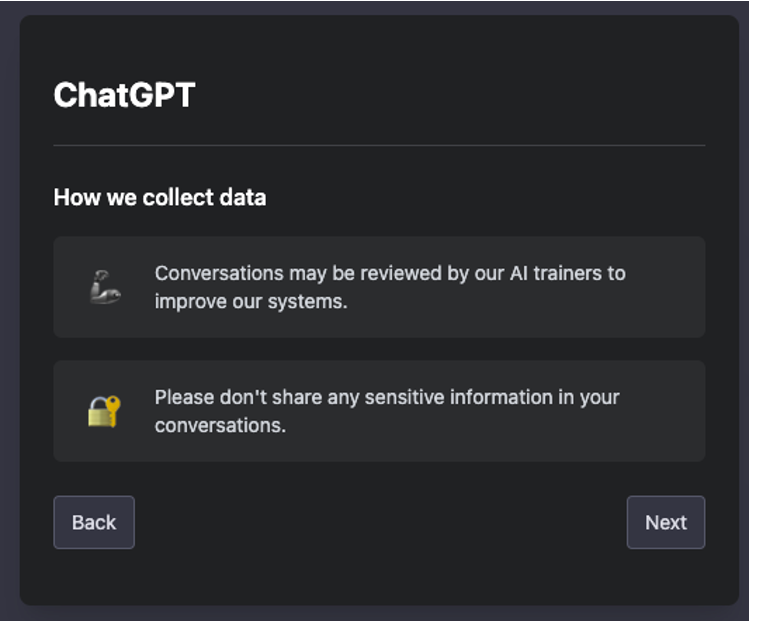
So they might have a look in your conversations. And if you look a bit further into their terms of use (you probably didn’t, but I did, so you don’t have to) you’ll find this part:
(c) Use of Content to Improve Services. We do not use Content that you provide to or receive from our API (“API Content”) to develop or improve our Services. We may use Content from Services other than our API (“Non-API Content”) to help develop and improve our Services. You can read more here about how Non-API Content may be used to improve model performance. If you do not want your Non-API Content used to improve Services, you can opt out by filling out this form. Please note that in some cases this may limit the ability of our Services to better address your specific use case.
Source: https://openai.com/policies/terms-of-use. You can also read more about how OpenAI uses the conversations to improve their models here.
This is written in legal lingo, but the use of ChatGPT falls under the “Non-API Content” bucket meaning that conversations you have with ChatGPT could potentially be used to improve the system. The process of “improving the system” could entail two things.
The first possibility is in the process called reinforcement learning with human feedback (RLHF). This is part of the training and optimization process of large language models. As stated, the core of the “knowledge” of GPT-3.5 and GPT-4 comes from the large amounts of text it has been fed with in its initial training.
After the AI has been fed with an enormous amount of texts and by itself identified relevant patterns about language, physics, economics and so on, human AI trainers engage in conversations, playing both the user and the AI assistant roles. Trainers also provide ratings for different model-generated responses to guide the AI in learning quality responses. This initial dialogue data is mixed with the rest of the training data, forming a dataset that the model can learn from.
The AI model's behaviour is then fine-tuned using a method called Proximal Policy Optimization, while the model is also periodically ranked and rated by human AI trainers to create a reward model for reinforcement learning. This iterative process, with constant feedback, reinforcement, and fine-tuning, helps train the AI to respond in a more human-like and useful way.

Even though OpenAI does not directly state how they use the users’ conversations with ChatGPT, it is very likely that they aggregate some of the learnings from the conversations and use them to understand how to improve the reinforcement learning process. This does not mean that the model gets any new knowledge or information from the conversations the users have, but rather that the model better understands how to answer questions, how to be polite in the right way, and so on.
That is one possible way of improving the model. Another possible use of the users’ conversations with ChatGPT is to improve future language models (e.g. GPT-5).
The second way user conversations can be utilised is in improving future language models, like a potential GPT-5 or beyond. This process is more indirect than the RLHF method but can still significantly contribute to the quality of the responses from the AI.
When training a new model, the data used is typically a massive compendium of publicly available text, including books, articles, websites, and more. This data is essentially the 'knowledge base' from which the AI generates its responses. If OpenAI decided to use aggregated and anonymized data from user conversations with ChatGPT, it could potentially be a part of the training set for a future model.

This does not mean that the AI would 'remember' specific conversations or be able to link them back to individual users. The process of training a model involves feeding it billions of words of text, which it then uses to learn patterns in language, context, and responses. This vast sea of text is anonymized and aggregated, so the model has no knowledge of the individual sources.
There is, however, a legitimate question to be asked about the quality of data that could be gleaned from user conversations with ChatGPT. While these dialogues certainly reflect a wide array of topics and conversational styles, they are also inherently skewed by the nature of the platform. Many users engage with ChatGPT for purposes such as writing assistance, factual inquiries, hypothetical scenarios, or even just casual banter out of curiosity. These interactions, while diverse, might not accurately represent the full spectrum of human dialogue and context.
Furthermore, conversations with an AI may be prone to certain types of responses or subjects that wouldn't typically emerge in human-to-human dialogues. Consequently, such data could introduce biases or limitations into the training set. Considering these potential drawbacks, one might wonder whether OpenAI would indeed find value in using this type of data for model training, or whether they would opt for a more curated and balanced dataset drawn from other sources.
Additionally, there's an important question concerning the circularity of using one language model to train another. Since ChatGPT is itself a product of machine learning algorithms and massive training datasets, utilising the interactions it generates for further training could lead to a kind of feedback loop. Could this result in compounded errors or biases that were present in the original model? Or could it lead to the perpetuation of certain patterns of responses, resulting in a loss of diversity in how the AI interacts? It's essentially using an AI's understanding of language — which, while impressive, is still fundamentally different from human understanding — to further train an AI. This could conceivably limit the potential of the new model to evolve beyond the capabilities and limitations of its predecessor. So it is - at least in my view - rather questionable whether OpenAI would gain any major benefits of using past conversations with ChatGPT to train future language models compared to finding other higher quality training materials such as licensed materials from books, newspapers or magazines, just to name a few.
To wrap up the past few sections, OpenAI could potentially use the users’ conversations with ChatGPT e.g. to improve their existing models in the RLHF process or as training material for future language models (beyond GPT-4). Though I do not see these two possibilities as very likely, when accepting the terms from OpenAI, you at least allow OpenAI to store the content of your conversations and human beings to look in your conversations. And that can be a problem by itself, especially if you are dealing with very personal or highly confidential information.
Sending confidential information to third party tools should probably be refrained from in all cases. Large corporations such as Samsung, Apple, Verizon, JPMorgan, and many more, recognizing these risks, have accordingly limited their employees from using these services. And if you are dealing with something very confidential such as the source code of important software in large organisations, tools like ChatGPT, while incredibly useful, may not be appropriate.
Alright, but what can you then do about it? Should you just completely avoid using AI tools like ChatGPT, if you work with sensitive data? Luckily, there are some quite easy things you can do to mitigate the risks of leaking sensitive information, when working with AI tools. One option is to remove the confidential parts of the text you want to send to ChatGPT before sending it. Another option is to opt out of getting your messages stored in ChatGPT, as this is actually easily done. Lastly, you can consider getting your own chatbot, where you control the data, storage and so on.
Before sending any information to a language model like ChatGPT, consider cleaning out sensitive information locally. Typically, the large majority of a piece of text or other data points are actually not confidential or personal. By replacing the few pieces of the text containing the confidential information with dummy data, you can use tools like ChatGPT without any problems.
OpenAI recently made it possible to opt out of getting the conversations stored. These new controls enable users to turn off their chat history, thereby opting out of providing their conversation history as data for training AI models.
These new controls, which are available to all ChatGPT users, can be located in the ChatGPT settings. For conversations initiated with the chat history disabled, these will neither be used for training and improvement of the ChatGPT model, nor will they appear in the history sidebar. Despite this, OpenAI will retain these conversations internally for a period of 30 days, reviewing them only as necessary to monitor for abuse before permanently deleting them.
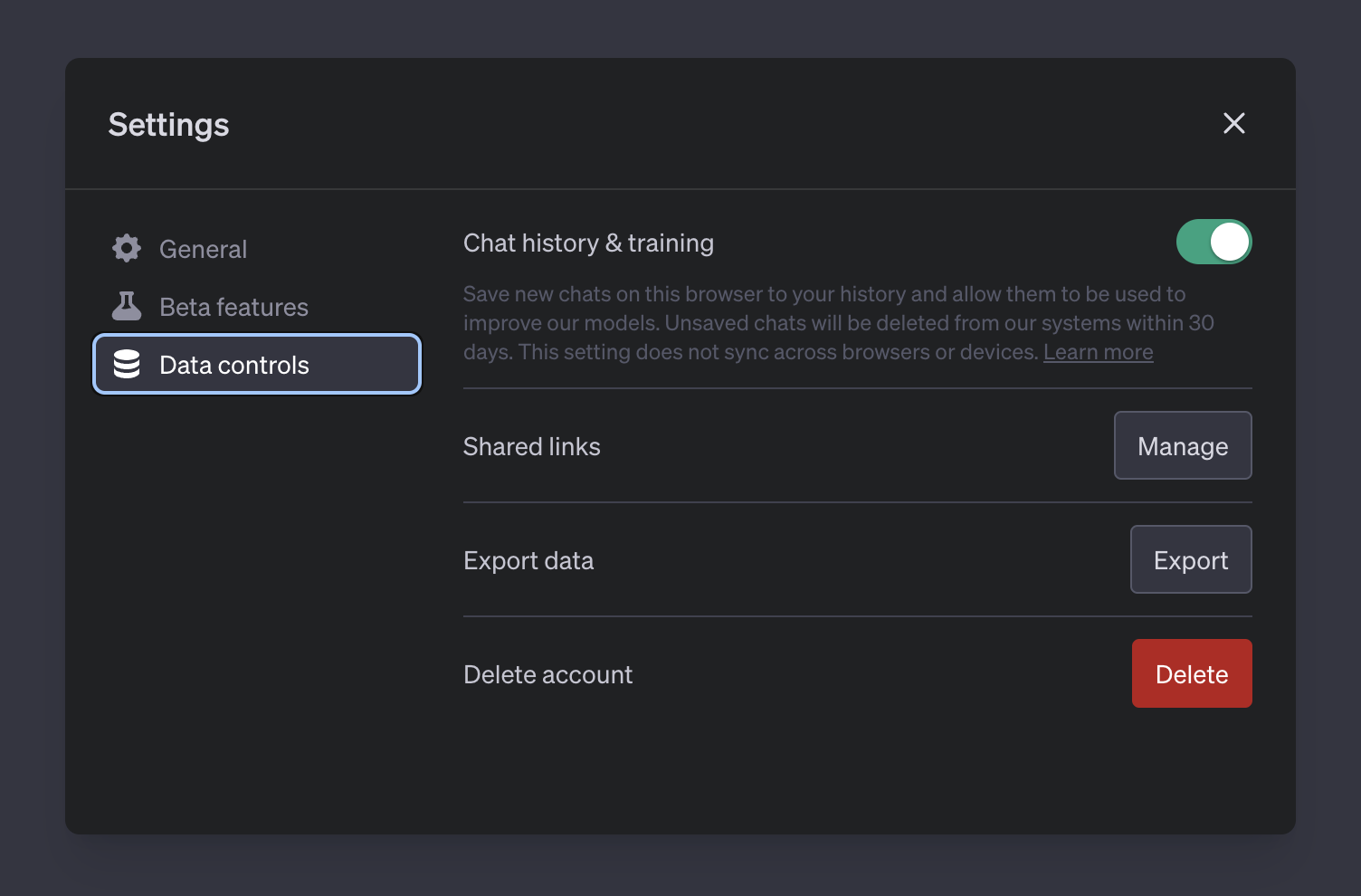
Users who choose to opt out of providing their data to OpenAI for training purposes will however not be able to use the conversation history feature, so you will lose the ability to go back in old conversations, if you chose to opt out of conversation storage.
If your company is particularly interested in utilising the capabilities of AI, but you have concerns about confidentiality and control of data, there's another solution: Applai Chat. Applai Chat provides organisations with their own customised AI-powered chatbot, based on the same foundation as ChatGPT.
- "Ah, so Victor, you wrote all of this only to tell about your own chatbot?"
Well, not only to tell you about our chatbot solution (which is really cool by the way!). But now that I have your attention...
One of the most attractive features of Applai Chat is the fact that your company maintains full control over the data. You decide what information the chatbot has access to, how it's stored, and where it's used. This approach aligns perfectly with organisations that place a high priority on data privacy and security, providing peace of mind while also reaping the benefits of AI technology.
But the advantages don't end there. Applai Chat can also be hooked up with your company's own data sources. This includes resources such as your website, internal documentation, knowledge base, and more. By doing this, Applai Chat can learn from these resources and deliver more precise and contextually accurate responses. The result? A chatbot that not only understands language at the level of ChatGPT but also has intimate knowledge of your specific company, industry, or customer base.
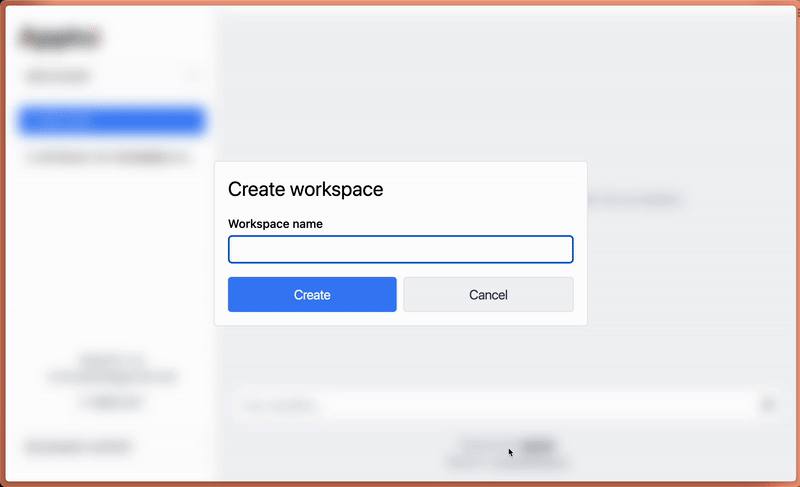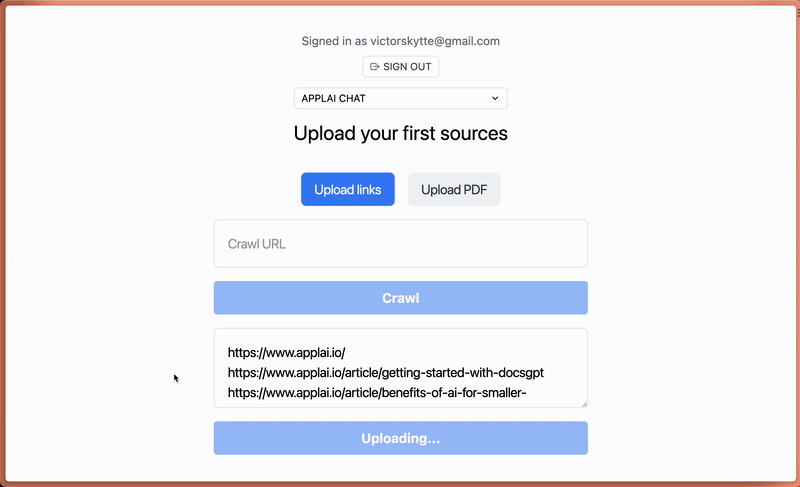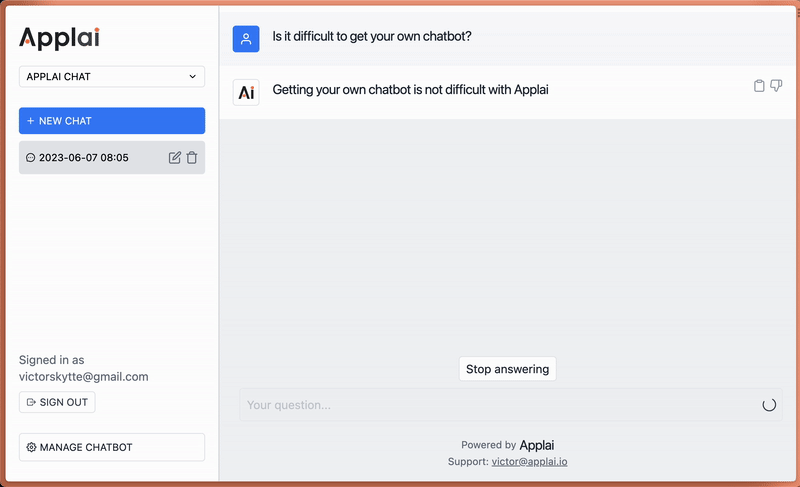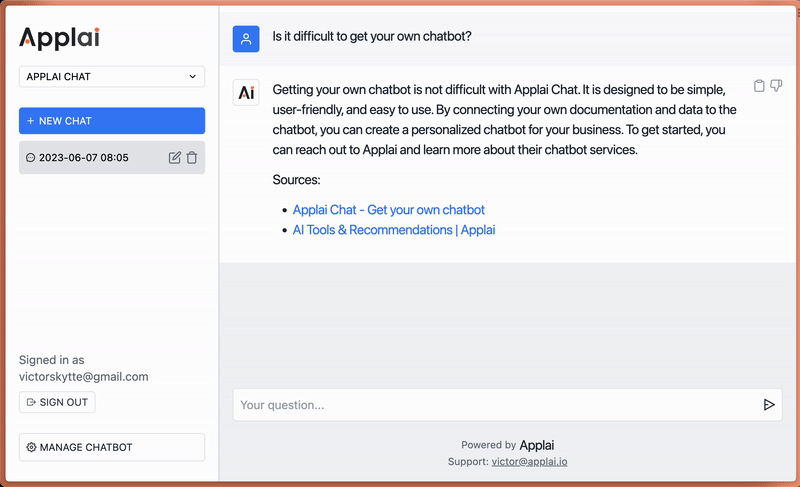
So, how does this work in practice? Imagine a customer asking your Applai Chat-powered bot about a specific feature of your product. Instead of providing a generic answer, the bot could draw from its knowledge of your product documentation and website to provide a detailed, accurate response. Or, a staff member could ask about a particular internal process, and the bot, drawing from your internal knowledge base, could guide them step-by-step through the procedure. It's like having ChatGPT, but tailored with your own data.
In Applai, we both guide companies on how to use AI for their work in a smart way as well as develop tailor-made AI solutions like Applai Chat, so you are very welcome to reach out, if you would like to hear more or have any questions. Get in touch with us here.